Pydantic AI Integration
PydanticAI is a framework that helps developers build structured, typed, and auditable AI agents. It provides strong input/output validation, enforcement hooks, and tool-oriented design patterns.
This guide demonstrates how to integrate policy-based authorization directly into AI agents using an ABAC (Attribute-Based Access Control) model, defining user roles, attributes, and resource permissions, and then enforcing them using Permit's SDKs and Policy Decision Point (PDP).
This guide uses Permit's Four Perimeter Model for AI Access Control.
These perimeters help ensure:
- Only eligible users can interact with your AI agent
- Sensitive data is protected based on user roles
- External actions are never triggered without authorization
- Outputs are policy-compliant before reaching the user
By the end of this tutorial, you'll have a fully operational, policy-governed AI agent with attribute-based authorization.
The full source code for the financial advisor agent is available here: Secure Financial Advisor AI Agent
Prerequisites and Tech Stack
Required Tools & Technologies
| Tool / Service | Purpose |
|---|---|
| PydanticAI | Framework for building structured AI agents |
| Permit.io | Authorization-as-a-service with policy-based access control |
| Anthropic / OpenAI | LLM API for financial assistant |
| Docker | To run the Permit PDP locally |
| Python 3.9+ | For executing the PydanticAI agent code |
| Poetry | (Optional) Python dependency management |
Required Environment Variables
Configure the following environment variables in a .env file or your shell environment:
PERMIT_KEY=<your-permit-api-key>
PDP_URL=http://localhost:7766 # Or use the Cloud PDP URL
These are automatically loaded via Python's dotenv utility:
from dotenv import load_dotenv
load_dotenv()
For a PDP setup guide, see Permit PDP Overview
Required Credentials
- Permit API Key – Available in the Permit.io dashboard under Settings → API Keys
- PDP URL – Typically
http://localhost:7766for local PDP; cloud options are available - AN Anthropic or OpenAI API Key for your LLM agent
Planning Our Policies
Before writing any code, it's important to define the authorization model that governs how your AI agent behaves. For this tutorial, we’ll use a financial advisor agent as an example. We'll later implement our policies using Permit.io's no-code dashboard.
Here's what our access model looks like from a real-world perspective:
- Only advises users who explicitly opted in
- Only shows financial documents to cleared users
- Only allows portfolio actions for premium users
- Only appends disclaimers when required
To create actual policies based on these requirements, let's map out our resources, attributes, actions, and condition/roles/user sets:
Defining Resources
| Resource Name | Purpose | Key Actions |
|---|---|---|
financial_advice | AI-generated investment suggestions | receive |
financial_document | Internal knowledge base documents | read |
portfolio | A user's financial assets | view, update |
financial_response | The AI-generated output shown to the user | requires_disclaimer |
Each resource can have attributes that help drive dynamic access checks:
financial_document.classification:public,restricted,confidentialfinancial_response.contains_advice:trueorfalse
Defining User Attributes
| Attribute | Type | Description |
|---|---|---|
clearance_level | string | The user's permission tier: low, high, etc. |
opted_in | boolean | Whether the user accepted AI-based financial advice |
role | string | Role assigned to the user: premium_user, etc. |
Defining Condition Sets
-
AI Advice Consent Check:
user.opted_in == true -
Document Clearance Match:
user.clearance_level == resource.classification -
Sensitive Portfolio Access:
user.role == "premium_user" -
Response Disclaimer Required:
resource.contains_advice == true
Defining Roles & User Sets
We'll model two main user types:
| Role | Description |
|---|---|
premium_user | Can do everything: read docs, get advice, update portfolios |
restricted_user | Read public docs only, no external actions, no advice |
We'll also define:
- User Sets:
opted_in_users:opted_in == truehigh_clearance_users:clearance_level == "high"
- Resource Sets:
confidential_docs:classification == "confidential"ai_generated_responses:contains_advice == true
Having a clear understanding of the individual elements that comprise our policies, let's define their schema in Permit.io.
Install and Run the Permit PDP
To perform real-time authorization checks, you'll need to run a local Policy Decision Point (PDP):
docker pull permitio/pdp-v2:latest
docker run -it -p 7766:7000 \
--env PDP_API_KEY=<YOUR_API_KEY> \
--env PDP_DEBUG=True \
permitio/pdp-v2:latest
- Replace
<YOUR_API_KEY>with your Permit.io API Key - The PDP will be available at
http://localhost:7766
Permit.io Policy Setup
With our perimeters and policies mapped out, it's time to configure our authorization schema in the Permit.io dashboard. This includes defining resources, actions, user and resource sets, and ABAC rules.
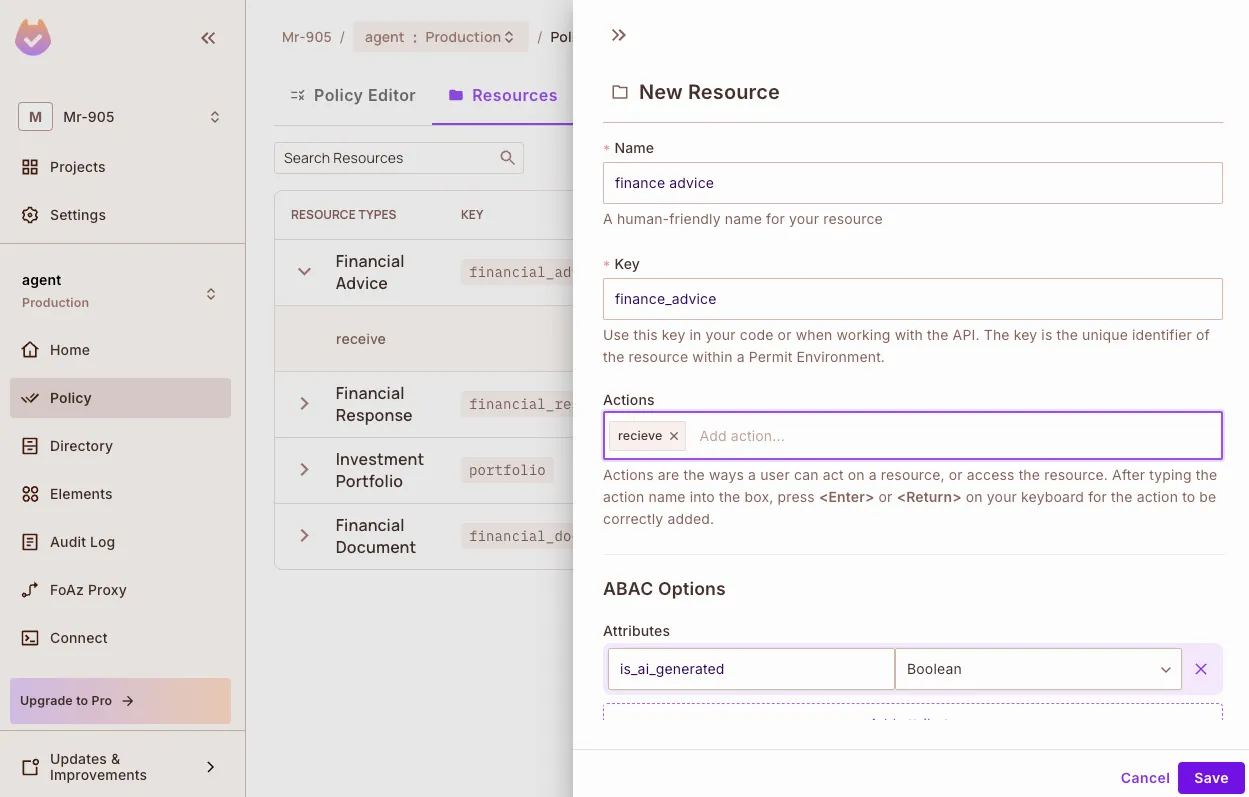
Define Resources Go to Policy → Resources, and define the following resources via the UI:
financial_advice
{
"actions": ["receive"],
"attributes": {
"is_ai_generated": "boolean"
}
}
financial_document
{
"actions": ["read"],
"attributes": {
"classification": "string", // e.g. public, restricted, confidential
"doc_type": "string"
}
}
portfolio
{
"actions": ["view", "update"]
}
financial_response
{
"actions": ["requires_disclaimer"],
"attributes": {
"contains_advice": "boolean"
}
}
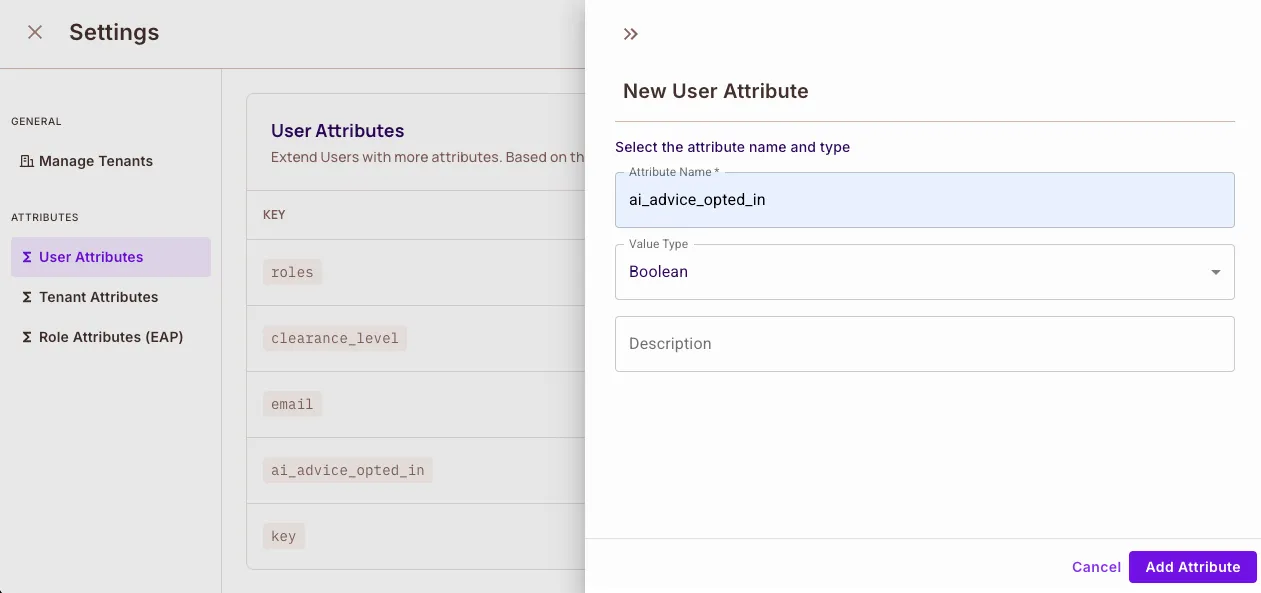
Add User Attributes Navigate to Directory → Users → Settings and define:
{
"opted_in": "boolean",
"clearance_level": "string",
"role": "string"
}
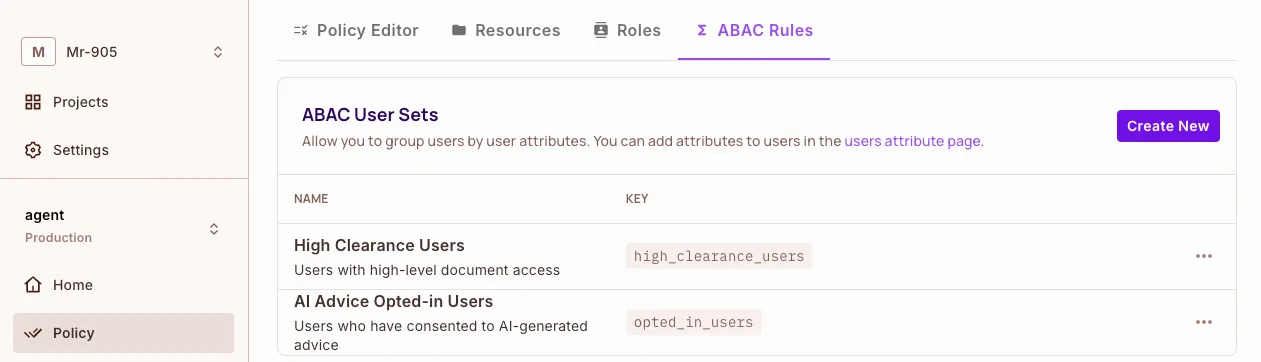
Create Condition Sets Go to Policy → ABAC → Condition Sets and define the following:
User Sets:
- Opted-in users who can receive AI advice
- High-clearance users for accessing
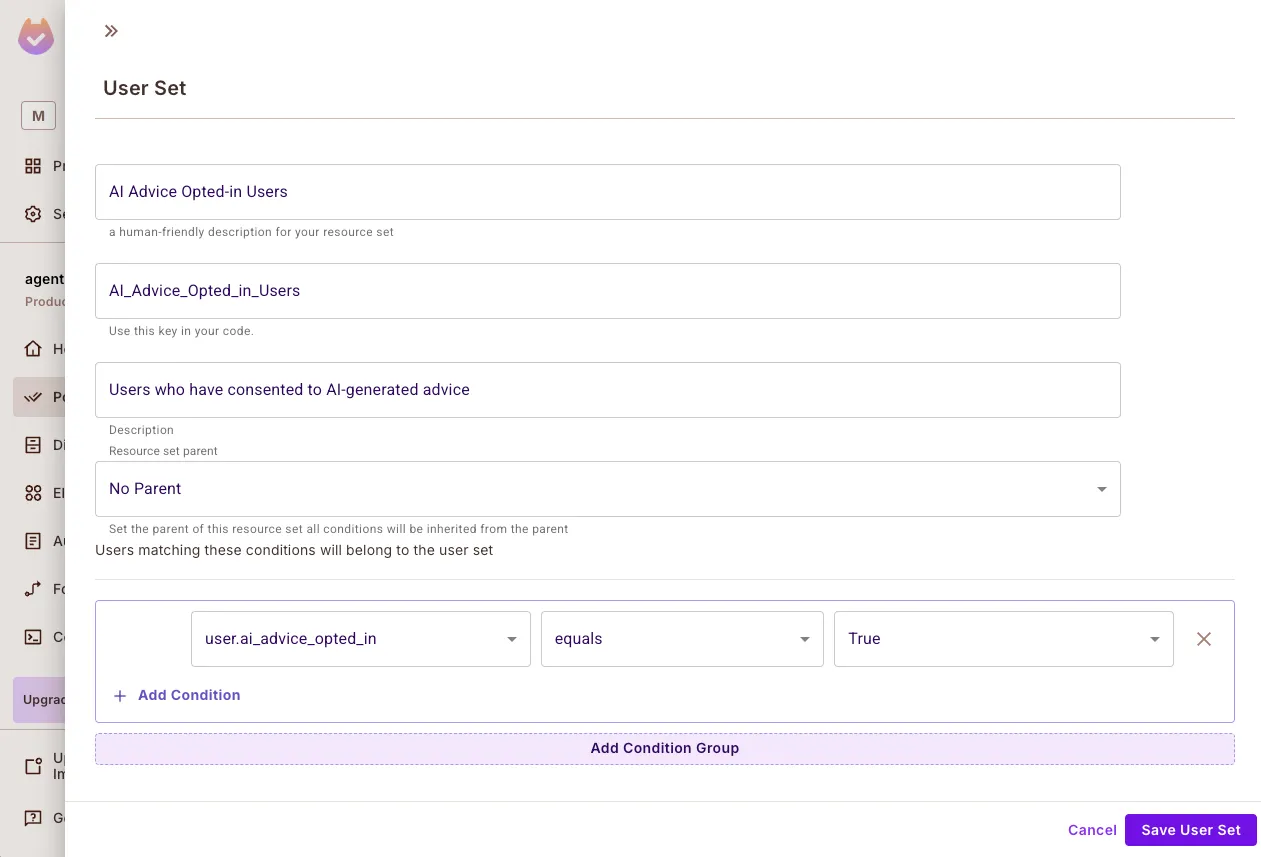
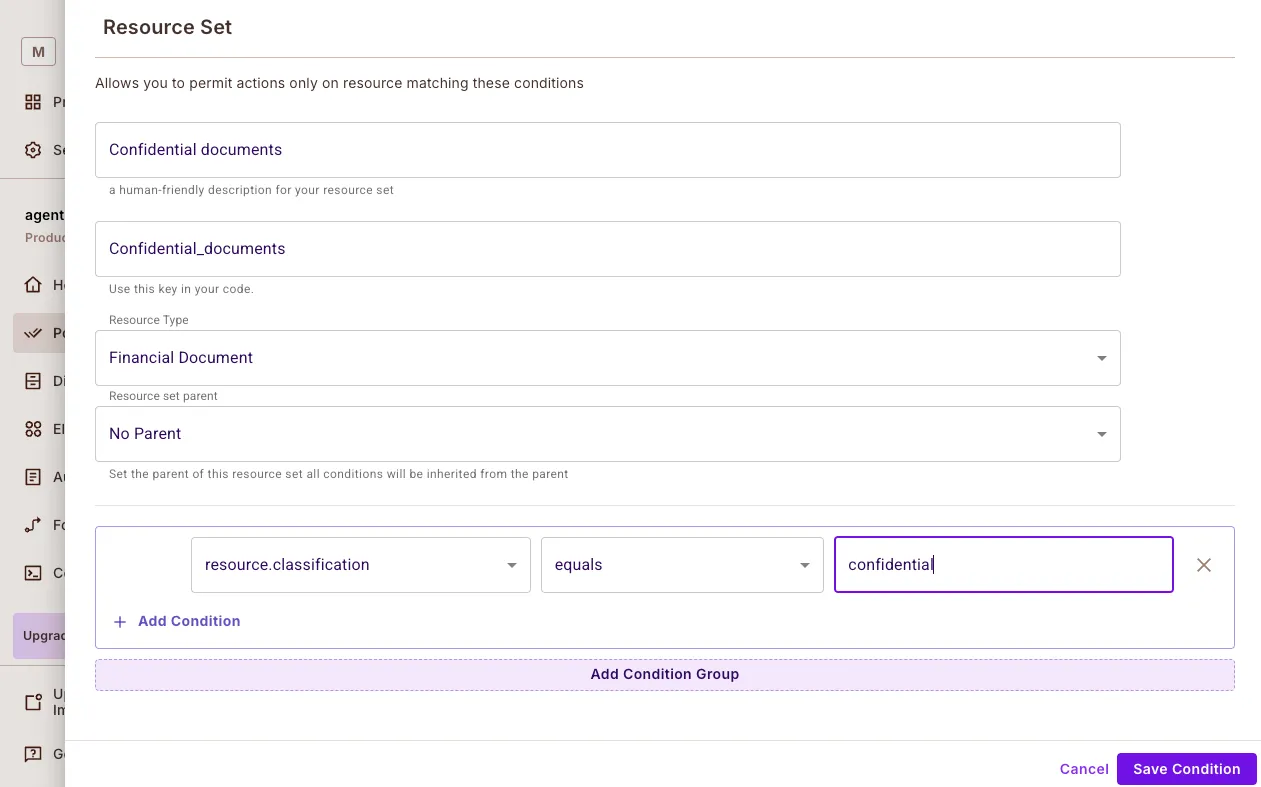
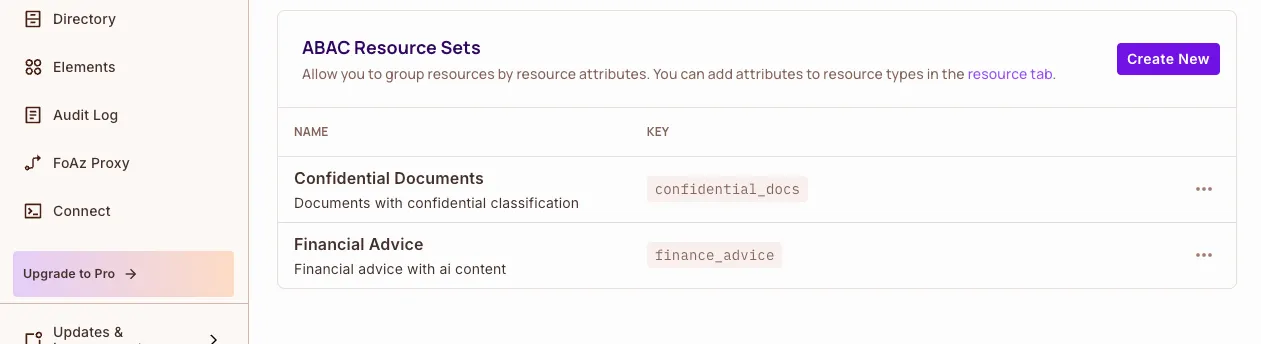
Resource Sets
- Confidential document classifications
- AI-generated advice content
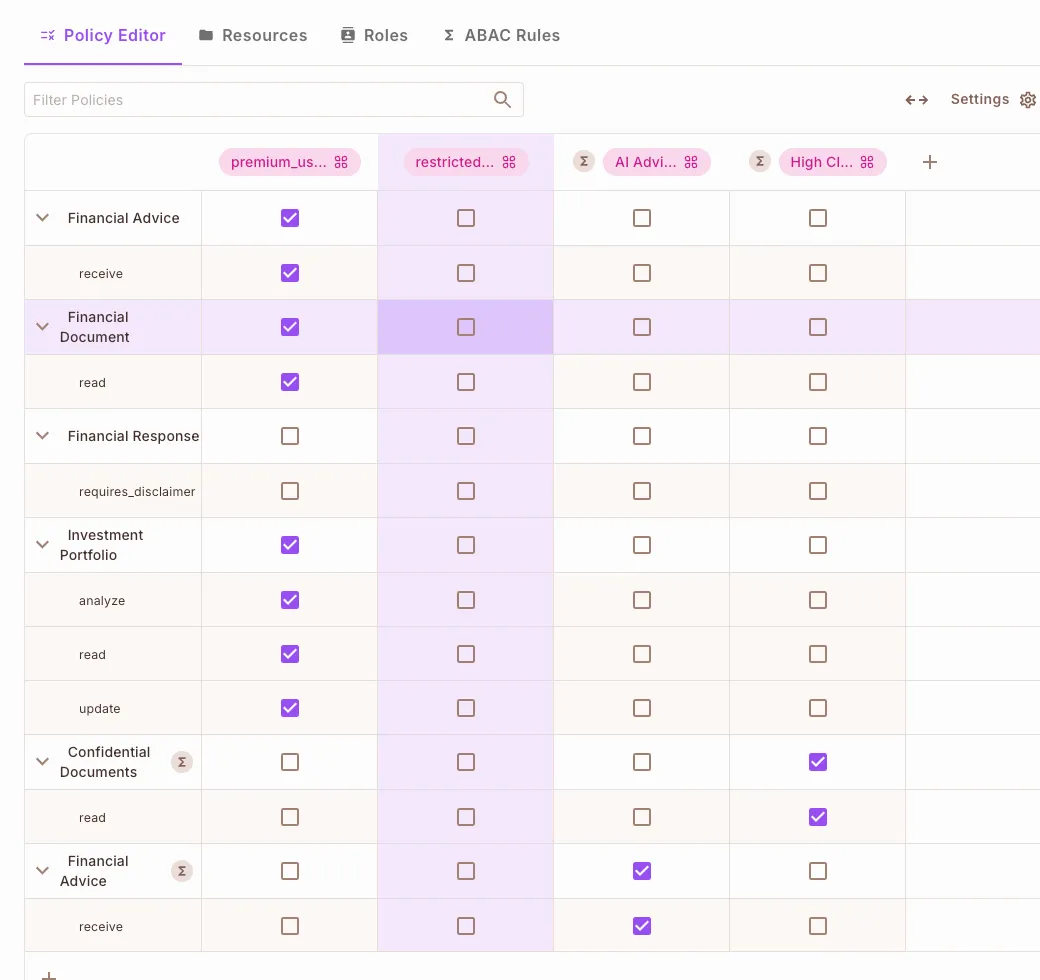
Policy Configuration
Here is what our Permit.io policy configuration dashboard looks like:
Use a Script Instead (Optional):
We can also set up the configuration by running the config.py file in the project repo:
python config.py
This creates:
- All required resources, attributes, and roles
- Sample condition and resource sets
- A usable policy matrix with attached rules
Once Permit.io is configured, you're ready to start building a secure AI agent with PydanticAI + Permit.
Prompt Filtering
Before a user query reaches the AI agent, we need to validate that it's allowed. Prompt filtering ensures:
- Users can only request actions they're authorized for
- Risky or sensitive prompts (like financial advice) are only handled for verified users
- Unauthorized queries are rejected early, before reaching the model
In this implementation, we'll validate that users are:
- Explicitly opted in for AI-generated financial advice
- Not requesting prohibited actions (e.g. investing guidance without consent)
How It Works
- Classify Prompt Intent – Detect whether a query is seeking financial advice
- Check Permissions – Use Permit to confirm the user has opted in
- Block or Allow – If allowed, continue. If not, return a denial message
Code Example: validate_financial_query
This function is called before processing user input in the agent:
@financial_agent.tool
async def validate_financial_query(
ctx: RunContext[PermitDeps],
query: FinancialQuery,
) -> Union[bool, str]:
"""SECURITY PERIMETER 1: Prompt Filtering
Validates whether users have explicitly consented to receive AI-generated financial advice.
"""
try:
# Classify the user's intent
is_seeking_advice = classify_prompt_for_advice(query.question)
# Perform the permission check with Permit.io
permitted = await ctx.deps.permit.check(
{"key": ctx.deps.user_id},
"receive",
{
"type": "financial_advice",
"attributes": {
"is_ai_generated": is_seeking_advice,
},
},
)
if not permitted:
return (
"User has not opted in to receive AI-generated financial advice."
if is_seeking_advice
else "User is not authorized for this type of query."
)
return True
except PermitApiError as e:
raise SecurityError(f"Prompt permission check failed: {str(e)}")
Classifying Financial Prompts
Here's the simple keyword-based prompt classifier:
def classify_prompt_for_advice(question: str) -> bool:
advice_keywords = [
"should I", "recommend", "advice", "suggest",
"what's the best", "help me choose", "better option"
]
question_lower = question.lower()
return any(keyword in question_lower for keyword in advice_keywords)
You can replace this with a more robust NLP-based intent classifier later.
Expected Behavior
| User | Prompt | Allowed? | Reason |
|---|---|---|---|
| Alice (opted-in) | "Should I invest in bonds?" | ✅ | Advice is allowed |
| Bob (not opted-in) | "What's a safe investment?" | ❌ | Advice blocked |
| Carol (opted-in) | "Tell me today's market news" | ✅ | Not advice-related |
| Dave (restricted) | "What's the best strategy?" | ❌ | Advice detected, no opt-in |
Data Protection
Once a user passes the prompt filtering stage, we need to restrict what information the AI agent can access based on the user's permissions.
This layer ensures:
- AI agents can only read documents a user is cleared for
- Sensitive knowledge (e.g., confidential reports, internal analysis) is never leaked to unauthorized users
- Each AI query dynamically filters the documents it sees
How It Works
- The user's request references a set of documents
- Permit checks each document's classification against the user's clearance level
- Only authorized documents are passed to the AI agent for context and generation
Code Example: access_financial_knowledge
This function runs before injecting documents into the AI's prompt or tool execution:
@financial_agent.tool
async def access_financial_knowledge(
ctx: RunContext[PermitDeps],
query: FinancialQuery
) -> List[str]:
"""SECURITY PERIMETER 2: Data Protection
Filters knowledge base access based on document classification and user clearance.
"""
try:
resources = [
{
"id": doc.id,
"type": "financial_document",
"attributes": {
"doc_type": doc.type,
"classification": doc.classification,
},
}
for doc in query.documents
]
# Use Permit to filter accessible documents
allowed_docs = await ctx.deps.permit.filter_objects(
ctx.deps.user_id,
"read",
{},
resources
)
allowed_ids = {doc["id"] for doc in allowed_docs}
return [doc.content for doc in query.documents if doc.id in allowed_ids]
except PermitApiError as e:
raise SecurityError(f"Failed to filter documents: {str(e)}")
Document Model & Classifications
Each document is modeled with a sensitivity level:
class FinancialDocument(BaseModel):
id: str
type: str # e.g., "report", "chart", "transcript"
classification: str # "public", "restricted", "confidential"
content: str
Permit.io will match the classification against user permissions to decide if the content can be shared.
Expected Behavior
| User | Document Classification | Access |
|---|---|---|
Alice (clearance: high) | confidential | ✅ |
Bob (clearance: low) | confidential | ❌ |
Carol (clearance: medium) | restricted | ✅ |
Dave (clearance: none) | public | ✅ |
This protects high-value data from being included in LLM prompts or output unless the user is explicitly allowed to see it.
Secure External Access
Your AI agent may interact with external systems — like APIs, databases, or third-party services — to retrieve or modify real-world data. This perimeter ensures those actions are only allowed when explicitly authorized.
This is especially critical for high-impact operations, such as portfolio updates, bank transactions, sensitive customer record edits, and triggering external workflows or webhooks.
Code Example: check_action_permissions
This tool checks whether the user is allowed to perform a particular external action (e.g., updating a portfolio):
@financial_agent.tool
async def check_action_permissions(
ctx: RunContext[PermitDeps],
action: str,
context: UserContext
) -> bool:
"""SECURITY PERIMETER 3: Secure External Access
Controls permissions for sensitive financial operations, such as modifying a portfolio.
"""
try:
return await ctx.deps.permit.check(
ctx.deps.user_id,
action,
{"type": "portfolio"}
)
except PermitApiError as e:
raise SecurityError(f"Failed to check portfolio update permission: {str(e)}")
This is a lightweight but powerful enforcement check — it runs before any real-world interaction.
Real-World Scenarios
| User Attributes | Attempted Action | Allowed? |
|---|---|---|
membership: basic | Modify investment portfolio | ❌ Denied |
membership: premium, verified: true | Modify investment portfolio | ✅ Allowed |
membership: premium, verified: false | Modify investment portfolio | ❌ Denied |
This ensures that portfolio updates (or any other external action) are never executed unless all security conditions are satisfied.
Combining with External APIs
This works in tandem with any service call:
if await check_action_permissions(...):
# Proceed to call API
result = await client.put("/portfolios/123", json=payload)
else:
raise SecurityError("Unauthorized portfolio update attempt.")
Response Enforcement
Even when the inputs, data, and actions are secure, the final AI-generated response must be validated before it's shown to the user. This ensures the AI doesn't leak sensitive data, violate regulations (e.g., offering financial advice without disclaimers), or create legal liability due to unfiltered content.
Code Example: validate_financial_response
This PydanticAI tool intercepts and inspects the final AI response before it's sent to the user:
@financial_agent.tool
async def validate_financial_response(
ctx: RunContext[PermitDeps],
response: FinancialResponse
) -> FinancialResponse:
"""SECURITY PERIMETER 4: Response Enforcement
Ensures all financial advice responses meet regulatory requirements
and include necessary disclaimers.
"""
try:
contains_advice = classify_response_for_advice(response.answer)
permitted = await ctx.deps.permit.check(
ctx.deps.user_id,
"requires_disclaimer",
{
"type": "financial_response",
"attributes": {"contains_advice": str(contains_advice)},
},
)
if contains_advice and permitted:
disclaimer = (
"\n\nIMPORTANT DISCLAIMER: This is AI-generated financial advice. "
"This information is for educational purposes only and should not be "
"considered professional financial advice. Always consult a qualified advisor."
)
response.answer += disclaimer
response.disclaimer_added = True
response.includes_advice = True
return response
except PermitApiError as e:
raise SecurityError(f"Failed to check response content: {str(e)}")
Response Classification
The system uses a simple keyword-based classifier to identify financial advice:
def classify_response_for_advice(response_text: str) -> bool:
advice_indicators = [
"recommend", "should", "consider", "advise",
"suggest", "best option", "strategy", "allocation"
]
return any(keyword in response_text.lower() for keyword in advice_indicators)
You can replace this with more advanced NLP or moderation APIs in production.
Once implemented, this perimeter gives you full confidence that every answer shown to your users is policy-compliant.
Running the Agent & Testing Behavior
With everything implemented, you're ready to run the AI agent and verify that its behavior matches your fine-grained policies. This section walks you through setting up the environment, launching the agent, and testing different user roles and permissions.
Start the Permit PDP Run the Permit Policy Decision Point (PDP) locally to enable real-time policy evaluations:
docker pull permitio/pdp-v2:latest
docker run -it -p 7766:7000 \
--env PDP_DEBUG=True \
--env PDP_API_KEY=<YOUR_API_KEY> \
permitio/pdp-v2:latest
Replace <YOUR_API_KEY> with your key from Permit.io dashboard → Settings → API Keys.
You may also use the cloud PDP by setting PDP_URL=https://cloudpdp.api.permit.io.
Launch the Agent Clone the repo and install dependencies:
git clone https://github.com/permitio/langchain-permit # Update if different
cd langchain-permit/pydantic-ai-examples
poetry install # Or use `pip install -r requirements.txt`
Then start the secure financial agent:
poetry run python -m pydantic_ai_examples.secure_ai_agent
This will start a CLI tool that simulates user queries and applies all four perimeters during execution.
Environment Setup
Ensure you have the required environment variables in a .env file or export them manually:
PERMIT_KEY=your-permit-api-key
PDP_URL=http://localhost:7766
These will be automatically loaded by the agent using dotenv.
Try Simulated Users Use test users with different roles and attributes to observe how the perimeters respond:
Fully Authorized Premium User:
{
"sub": "user-001",
"attributes": {
"membership_tier": ["premium"],
"clearance_level": "confidential",
"opted_in": true}
}
Result: Can access documents, request advice, execute actions, and see disclaimers when needed.
Limited Basic User
{
"sub": "user-002",
"attributes": {
"membership_tier": ["basic"],
"clearance_level": "restricted",
"opted_in": false}
}
Result: Blocked from advice, sensitive documents, and bookings.
Test Inputs & Validate Results
Try asking:
- "What's the best investment strategy in a recession?"
- "Can I get a breakdown of my current portfolio?"
- "What documents do I need to file taxes as a freelancer?"
Then watch:
- The input gets classified
- Permissions are checked
- Data is filtered or denied
- Responses are validated and modified with disclaimers if needed
You can view allow/deny logs in the Permit Audit Logs panel for each perimeter in real time.
Behavior Summary Table
| Feature | Premium User | Basic User | Not Opted-In |
|---|---|---|---|
| Ask for financial advice | ✅ Allowed (with disclaimer) | ❌ Blocked | ❌ Blocked |
| Access confidential docs | ✅ Allowed | ❌ Blocked | ❌ Blocked |
| Modify investment portfolio | ✅ Allowed | ❌ Blocked | ❌ Blocked |
| Generic public info | ✅ Allowed | ✅ Allowed | ✅ Allowed |
Final Thoughts & Resources
By combining PydanticAI and Permit.io, you've implemented a layered access control model that protects every part of the agent workflow: from what users say, to what data the model uses, what it's allowed to do, and how it responds.
By following this guide, you've learned how to:
- Model fine-grained ABAC policies in Permit.io using attributes like
membership_tier,opted_in, andclearance_level - Enforce Prompt Filtering: Block unauthorized input before it reaches the LLM
- Apply Data Protection: Dynamically filter documents based on user roles
- Secure External Access: Authorize sensitive operations like portfolio updates
- Validate Responses: Ensure compliance with disclaimers and advice checks
This architecture ensures your AI agents respect organizational rules, user permissions, and regulatory boundaries, without sacrificing flexibility or developer experience.
Further Reading & Resources
- GitHub: Try the full agent example
- GitHub: Read the agent docs
- Blog: AI Agent Access Control Overhaul with PydanticAI
- Got Questions? Join the Permit.io Slack Community